CLUBS
An RGB-D Dataset with Cluttered Box Scenes Containing Household Objects
Autonomous Systems Lab, ETH Zurich, Switzerland

Autonomous Systems Lab, ETH Zurich, Switzerland
DATASET:
CLUBS is an RGB-D dataset that can be used for segmentation, classification and detetion of household objects in realistic warehouse box scenarios. The dataset contains the object scenes, the reconstructed models, as well as box
scenes that contain mutliple objects packed in different configurations. Additionally, the raw scaning data, 2D object bounding boxes and pixel-wise labels in RGB images, 3D bounding boxes, and calibration data are also available.
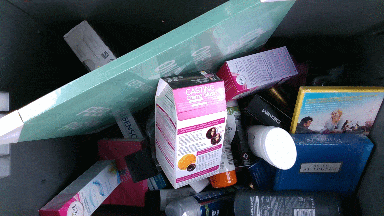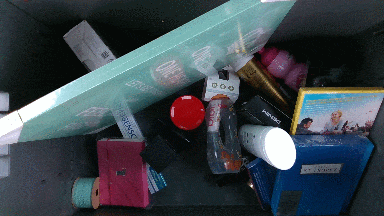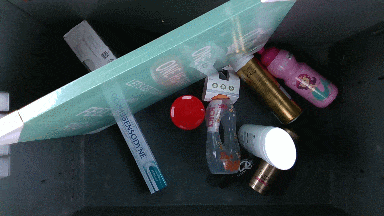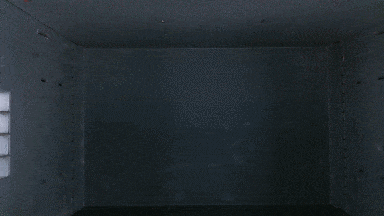
The dataset contains 85 object scenes and 25 box scenes. Different box scenes have diffrent configurations of objects in them and vary in clutter level. More details about the specific box scenes can be found by clicking on the scene gif image in the Box scenes section below.

Object scenes
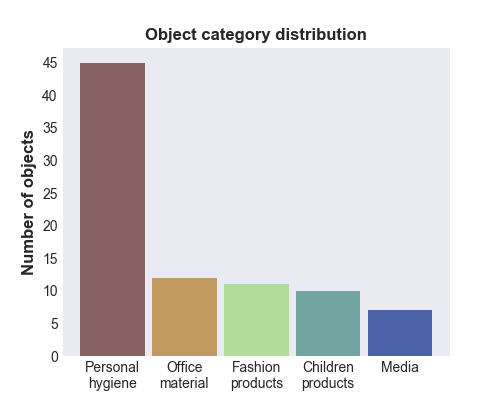
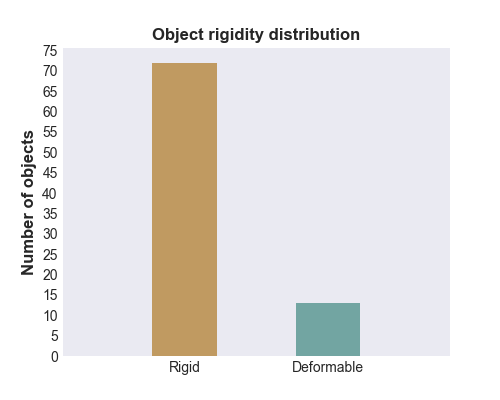
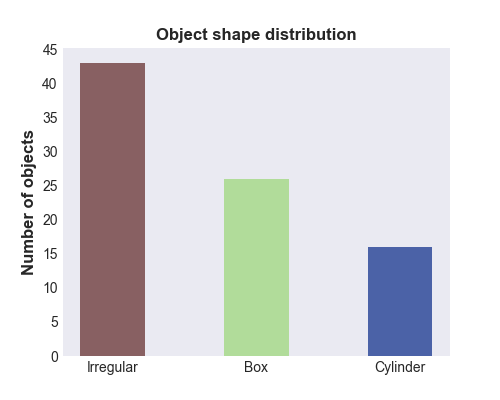
The dataset contains 85 different objects. The path for scanning a single object scene contains 19 different poses at three different height levels. It covers the whole object from every side, except the bottom. Every object was,
therefore, rotated and scanned a second time to also cover the bottom face.





Box scenes
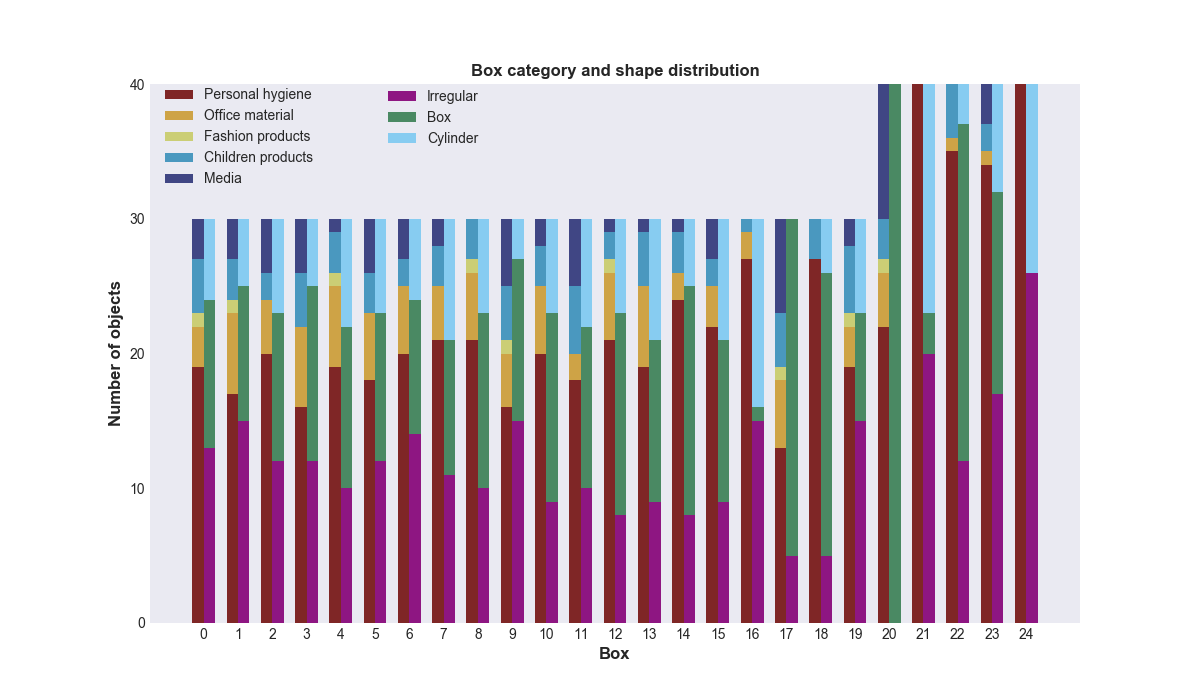
The robot path for box scenes is shorter and contains 9 poses. These poses were chosen such that the inside of a box of size 58x38x34 cm is covered from all sides including a top-view. The dataset contains 25 different box scenes,
where 5 of them have 40 objects and rest 30 objects. Overall object distribution within the boxes is shown below:
























Calibration
All the raw calibration data and results are available for download below. For the distortion, radial-tangential model was used, represented as:
- - calibration
- - primesense.yaml
- - realsense_d415_device_depth.yaml
- - realsense_d415_stereo_depth.yaml
- - realsense_d435_device_depth.yaml
- - realsense_d435_stereo_depth.yaml
- - chameleon3.yaml
- - calibration_raw_data
MATLAB script for obtaining the calibration parameters is available on the clubs_dataset_tools github page.
Notation and data structure
Camera poses are represented by a translation vector and a Hamiltonian unit quaternion:
- - scene
- - scene_objects.csv
- - W_H_poses.csv
- - sensor
- - W_RGB_poses.csv
- - W_IR1_poses.csv
- - W_IR2_poses.csv
- - depth_images
- - stamp_depth.png
- - ir1_images
- - stamp_ir1.png
- - ir2_images
- - stamp_ir2.png
- - rgb_images
- - stamp_rgb.png
- - labels
- - rgb_images
- - stamp_rgb_label.json
- - stamp_rgb_label.png
- - scene_sensor_pointlcoud.ply
For each sensor in one scene, we provide the reconstructed point cloud scene_sensor_pointcloud.ply obtained by integrating the point clouds with their corresponding camera poses into a TSDF volume. The pixel-wise labels and 2D
bounding boxes are stored in json files timestamp_rgb_label.json as follows:
{"poly":
[[[x00, y00], ..., [x0L, y0L]],
...,
[[xN0, yN0], ..., [xNL, yNL]]],
"bbox":
[[bx0, by0, w0, h0],
...,
[bxN, byN, wN, hN]],
"labels":
["label0",
...,
"labelN"]}PUBLICATION:
If you are using this dataset in your research, please cite the following publication:
@article{novkovic2019clubs,
author = {Novkovic, Tonci and Furrer, Fadri and Panjek, Marko and Grinvald, Margarita and Siegwart, Roland and Nieto, Juan},
journal = {The International Journal of Robotics Research (IJRR)},
title = {CLUBS: An RGB-D dataset with cluttered box scenes containing household objects},
year = {2019},
pages = {1538-1548},
volume = {38},
number = {14},
doi = {10.1177/0278364919875221}
}
DOWNLOAD:
Individual object scenes can be downloaded from the list in the Object scenes section. Furthermore, individual box scenes can be downloaded by clicking on the scene image in the Box scenes section. Finally, the whole dataset can be downloaded using the following links:
TOOLS:
This dataset comes with a set of tools which are avilable on our repo:
clubs_dataset_tools
These tools include: